![]()
CHAPTER 4 - LULC DYNAMICS: THE COLONIZATION IMPACT
4.2. Methodological approach
Few political initiatives have had the social, economic and environmental impact of rural colonization projects in the Brazilian Amazon. Despite its importance, examples of planning and monitoring of settlements in the region using geoprocessing techniques to understand the trajectory of those landscapes in transformation are rare. This chapter builds on research carried out at Indiana University, through a framework based on the integration of remote sensing data and anthropological and ecological research in a geographic information system that allows spatial and temporal analyses in several levels and scales. The main goal of this initiative is to understand LULC dynamics in Machadinho and Anari, enriching the debate about planning and monitoring strategies of rural settlements in Amazônia.
In general terms, the methodological approach involved the need to investigate colonization processes within the study area and their environmental implications regarding LULC change. Thus, I intend to explain relationships between LULC dynamics and agroecological processes underlying landscape transformation. Remote sensing, GIS, and spatial analysis played a central role in providing elements for discussion. But how should one distinguish different units of analysis composing a settlement? This hierarchy depends on consideration of the mosaic of patches characterizing the settlement. In Amazonian rural settlements, the biophysical compartments, the socioeconomic context, and the spatial-temporal arrangements of occupation delimit fundamental units of analysis. Within this chapter, findings are presented with emphasis on settlement landscapes, reserves, buffers around roads, and property lots. The analytical strategy, summarized in Figure 47, includes several modules described as follows:
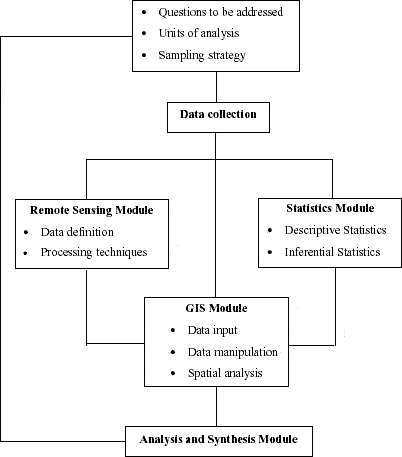
Figure 47 - Methodological steps for the study of LULC dynamics in Machadinho d’Oeste and Vale do Anari.
4.2.1. Multi-temporal analysis: What need have I for this?
It has been shown that deforestation trajectories in Amazonian settlements follow cycles related to stages of establishment, expansion, and consolidation of rural properties. The magnitude of these pulses is a function of lot allocation and condition, time of occupation, structure and composition of the domestic unity, and credit policies (Brondizio et al. in press).
In order to capture the spatial-temporal dynamics regarding LULC changes in Machadinho and Anari, I used satellite images beginning in 1988. This allowed the detection of earlier stages of lot occupation and deforestation, five years after the settlements' implementation. Starting with 1988, a ten-year period was defined to carry out the multi-temporal analysis. The choice of image dates and period of analysis was dependent on several factors. The goal was to depict deforestation processes and conversion to farmland, as well as vegetation regrowth to older stages of secondary succession. For this purpose, images dated 1988, 1994, and 1998 were used. The images were selected after a careful analysis of Landsat TM data availability, cloud cover, and data quality. All images were acquired in June, during the dry season, to allow a better differentiation between forest lands, areas in succession, and farmlands. Collection of training samples during fieldwork was carried out in 1999 and 2000 from June to August, also during the dry season.
4.2.2. Pre-classification techniques
Several pre-processing techniques were carried out prior to LULC classification. The first step was to correct geometric distortions present in the raw Landsat TM images. Geometric rectification is the process of image adjustment to a pre-established coordinate system (Lillesand and Kiefer 2000). A multi-step procedure was used to maintain consistency during the rectification process. First, the three images were registered together based on control points identifiable in all of them. Then, all bands of all images were combined in a single file and geometrically rectified based on control points taken from topographic sheets at 1:100,000 scale using a UTM projection. The algorithm used for coordinate transformation was nearest neighbor, which applies a regression model to determine the coefficient for the transformation equations in x and y. The resampling technique directly assigns the digital number (DN) in the input file that most overlaps the pixel in the output file, maintaining its value (Richards 1993). The RMS (Root Mean Squared) error in all steps was always smaller than a half pixel.
Once geometrically rectified, the images were separated to perform atmospheric correction. When using multi-temporal TM data, atmospheric conditions can vary significantly both spatially and temporally as a result of molecular scattering and absorption. The objective of atmospheric correction was to convert remotely sensed digital numbers (DN) to ground surface reflectance in order to make the data spectrally comparable (Green et al. 2000). There are several methods addressing atmospheric correction issues (Markham and Baker 1986; Chavez 1988, 1996; Vermote et al. 1997). Some of the most accurate methods involve physically based models, which require atmospheric data coincident with remote sensing data acquisition. However, when these data are unavailable, image-based models are recommended. So, the Improved Image-Based Dark Object Subtraction (DOS) model was used (Lu et al. in press). The algorithm takes the atmospheric scattering and absorption into account, correcting the effects caused by path radiance and part of the atmospheric transmittance. The process can be used for atmospheric correction of remotely sensed data, especially for historical image data when atmospheric data are not available. The model is expressed by:

After geometric rectification and atmospheric correction, subsets were produced using the settlements' boundaries. Figure 48 summarizes the procedures described so far.
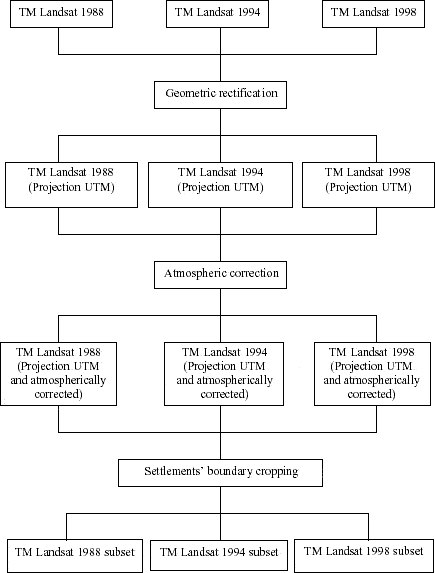
Figure 48 - Pre-classification techniques used for the study of LULC dynamics in Machadinho d’Oeste and Vale do Anari.
4.2.3. LULC classification
The transformation of spectral data into information through the extraction of thematic features has been traditionally done through classification techniques. Several textbooks present techniques for supervised or unsupervised classification, but they do not always indicate the need of emphasizing specific characteristics of each application (Woodcock and Strahler 1987).
The main difference between supervised and unsupervised classification is that the former requires the identity and location of some of the land cover to be known (Mausel et al. 1990), while the latter is based on automatic clustering of pixels with similar spectral characteristics according to statistically determined criteria (Jensen 1996).
The unsupervised classification requires only a minimal amount of initial input from the analyst. However, knowledge about the spectral characteristics of the terrain is necessary to label certain clusters as representing land-cover classes (Landgrebe and Biehl 1995). The supervised classification requires much more input from the analyst, including the collection of training samples, the generation of graphic methods for feature selection, and the selection of appropriate classification algorithms (Lillesand and Kiefer 2000).
Results obtained from the single use of standard classification techniques are not always sufficient, mainly in studies involving complex LULC features (Myers et al. 1989). An alternate approach to increase information content from original and enhanced data is to implement improved classification techniques and methods of analysis. It has been demonstrated that hybrid classification systems are frequently appropriate not only to track past deforestation, but also to see future trends of new agroecological processes (Lucas et al. 1998, McCracken et al. 1999, Brondizio et al. in press).
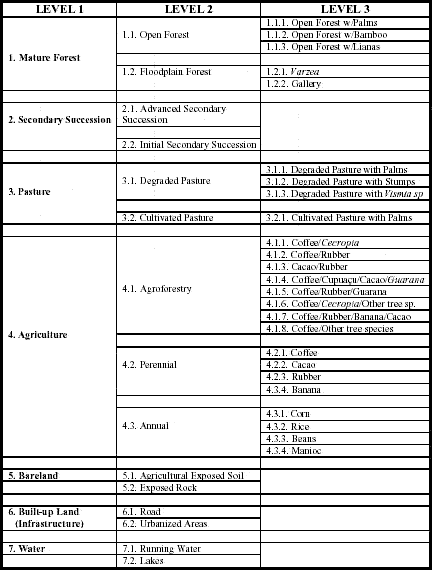
The method used for LULC classification in Machadinho and Anari was an example of hybrid solutions. The first step was to build a hierarchical classification system based on vegetation structure and physiognomy. The criteria for class definition used a multi-level approach (Anderson et al. 1976) and an official Brazilian classification system for vegetation features (Veloso et al. 1991). Table 12 summarizes LULC classes encountered during fieldwork. For the final classification, the first-level classes were adopted, except for secondary succession, for which two classes were used, as indicated by the results presented in Chapter 3. So, the final classes were: mature forest, advanced secondary succession, initial secondary succession, pasture, agriculture, bareland, infrastructure, and water. In 1988, just one class of regrowth was used. After just five years of settlement implementation, the advanced secondary succession stage would not be present.
Table 12 - LULC classification system for Machadinho d’Oeste and Vale do Anari.
The hybrid classification approach consisted of building spectral signature files derived from both unsupervised ISODATA techniques (ERDAS 1998) and supervised classification using training samples collected during fieldwork. All training samples were accurately integrated in the GIS/remote sensing environment through the use of a GPS (Global Positioning System) and associated software. The training sample protocol and fieldwork data collection was already described in Chapter 3. An important part of the process was to carry out interviews with local people to inform the classification of images dated 1988 and 1994.
Separability analysis on the signature files (ERDAS 1998) and analysis of vegetation structure (Brondizio 1996) were used to select the best signatures during the classification process. The spectral curves for all classes in each date show the responses obtained after all techniques used (Figures 49, 50 and 51). Once the best signatures had been selected, a maximum likelihood classification (Jensen 1996) was carried out for each date.
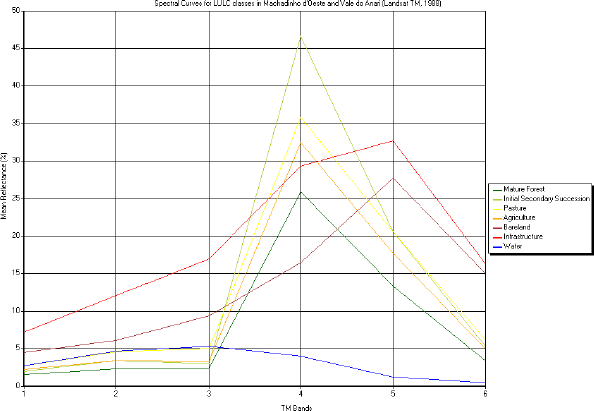
Figure 49 - Spectral curves for LULC classes in Machadinho d’Oeste and Vale do Anari (Landsat TM 1988).
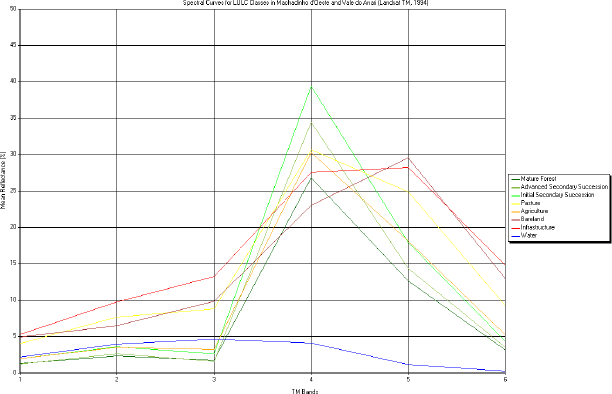
Figure 50 - Spectral curves for LULC classes in Machadinho d’Oeste and Vale do Anari (Landsat TM 1994).
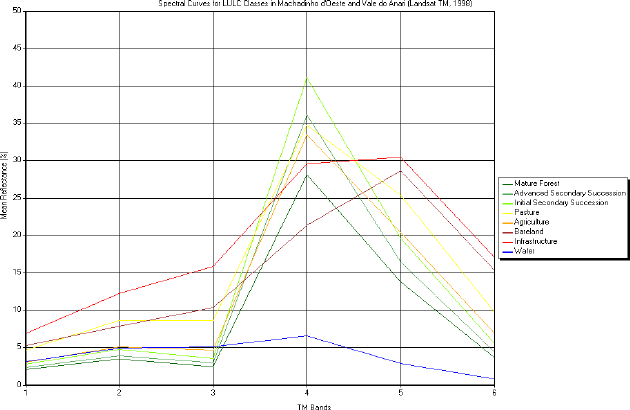
Figure 51 - Spectral curves for LULC classes in Machadinho d’Oeste and Vale do Anari (Landsat TM 1998).
4.2.4. Post-classification procedures and GIS manipulation
One of the main problems when classifying complex LULC features in the Amazon is related to the spatial configuration of agricultural fields, pasture, and different stages of secondary succession. Both the relatively small size of these patches and the mixed spectral responses of pixels representing their classes are responsible for data misclassifications. Recently, several initiatives have been implemented to overcome these limitations, including the use of data with higher spatial resolution (e.g., IKONOS), non-optical sensors (Rignot et al. 1997, Saatchi et al. 1997), the integration of detailed field data to support the classification process (Mausel et al. 1993, Li et al. 1994, Brondizio et al. 1996, Lucas et al. 1998), the use of spectral mixture analysis (Adams et al. 1995), object-based classifiers (Foody et al. 1996), indices (Steininger 1996), and hybrid techniques. Other problematic land covers to differentiate in the study area are the road network and urban areas. They are often confused with agricultural bare soil because most roads and urban areas are unpaved.
After going through the procedures described in the previous section, some adjustments were necessary to achieve a higher accuracy for the final LULC classifications. First, a 3 x 3 pixels neighborhood filter based on the majority rule was used to remove isolated pixels (ERDAS 1998). The procedure was carried out for all dates using identical rules and produced better cartographic results for the scale of study. To better map roads, urban areas, and rivers, topographic maps and visual interpretation were used to improve the classification in a GIS environment. Field notes and observations about LULC in the study area were always useful to inform decisions about the technical procedures to use.
The results were tested through accuracy assessment. A common method for classification accuracy assessment is the error matrix. The error matrix compares the relationships between ground-truth data (reference data) and classified results category-by-category. From the error matrix, some important measures can be derived, such as overall accuracy, producer's accuracy, and user's accuracy. Many works have provided the meanings and calculation methods for these measures (Congalton 1991, Richards 1993, Janssen and Wel 1994, Campbell 1996, Jensen 1996). Another method to interpret the classification accuracy is to calculate Kappa coefficients (Ma and Redmond 1995, Jensen 1996, Kalkahan et al. 1997). It measures the difference between the agreement between reference data and classification results and the chance of agreement between the reference data and a random classifier. The Kappa coefficient is computed as
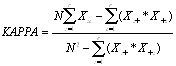
where r is the number of rows in the error matrix, is the number of observations in row i and column i in the error matrix (i.e., the corrected classified number), and are the marginal total in row i and column i respectively, and N is the total number of observations included in the error matrix.
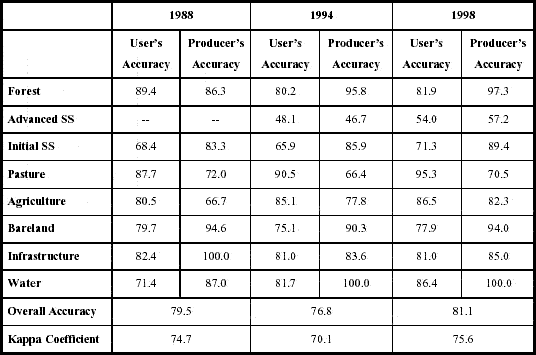
The results for the accuracy assessment of LULC classifications are listed in Table 13. Relatively higher values were found for the 1988 and 1998 classifications. The higher accuracy in 1998 is certainly due to the greater control over field data collected in 1999 and 2000. A considerable number of training samples were selected for this date based on ground truthing. In 1988, the use of just one class of secondary succession was responsible for a better discrimination between classes.
Table 13 - Accuracy assessment for LULC classifications in Machadinho d’Oeste and Vale do Anari.
After accuracy assessment, the classifications were integrated in a GIS to allow further manipulations and analyses. Areas were tabulated for each class and date. Transition matrices were performed to answer specific questions on LULC dynamics in Machadinho and Anari. Buffers of 100 m, 200 m, 400 m, and 800 m were created around the road network for manipulations and area calculations within these landscape corridors. Analyses with and without the extractive reserves in Machadinho were performed. Property grids were digitized for both settlements, allowing the extraction of LULC information at the property level. Layouts, tables, and graphics were produced, as presented in the next sections.